먼저 회원가입과 로그인 기본 요구사항은 다음과 같다.
- 로그인, 회원가입 전 먼저 휴대폰 인증을 완료한다.
- 휴대폰 인증 정보를 통해 가입된 유저인지 판단 후 가입된 유저면 --> 로그인 성공
- 가입되지 않은 유저라면 회원가입에 필요한 추가정보 입력페이지로 들어가서 회원가입을 한다.
- 로그인이 필요한 페이지는 로그인 하지 않은 사용자는 접근할 수 없어야 한다.
휴대폰 인증을 위해서 Firebase auth 기능을 사용했고, 사용자 로그인과 관리를 위해 Spring security의 기능들을 같이 활용하여 구현했다.
전체적인 백엔드 처리 흐름을 먼저 살펴보고 각 단계에서 어떤 코드가 어떤 일을 하는지 자세히 살펴보도록 하자.
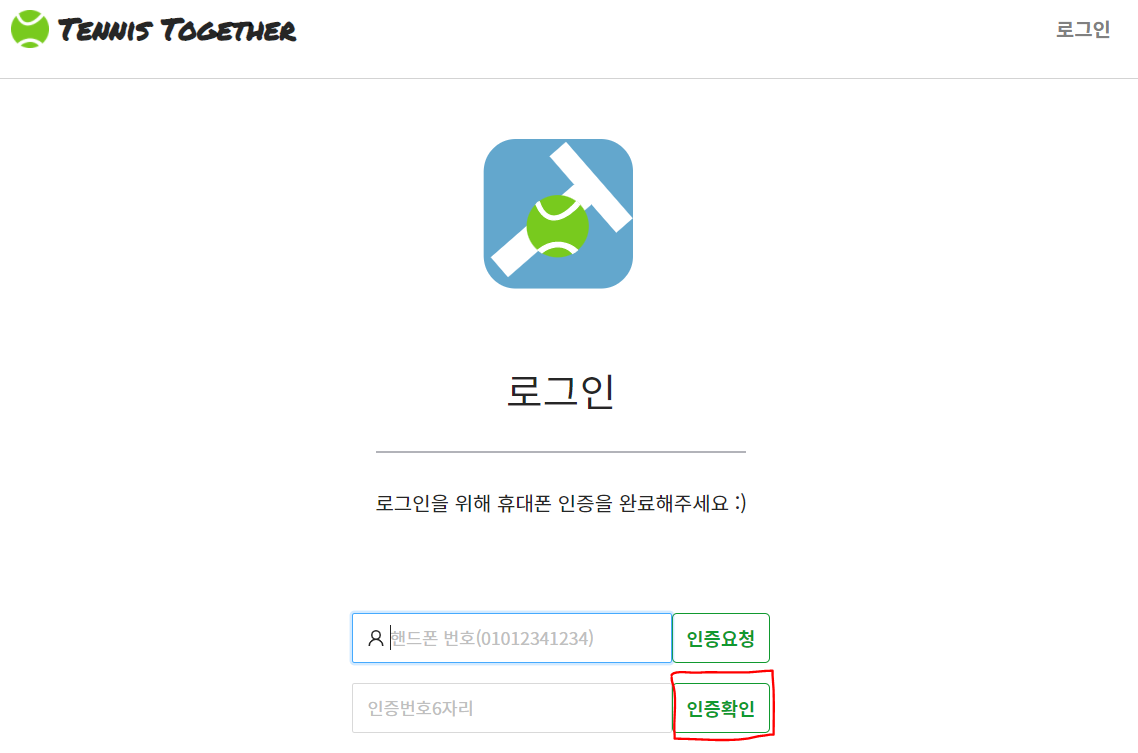
1. 먼저 유저가 휴대폰 인증을 완료한 이후 인증완료 버튼을 누르게 되면 로그인을 의미하는 http요청이 서버로 들어온다.
2. 이때 서버에서는 Spring Security의 필터가 이 요청을 가로채 먼저 검증이 필요한 요청인지 확인한다.
3. 검증이 필요한 요청이라면 해당 유저의 로그인 정보를 검증하는 사용자 정의 필터인 JwtFilter가 실행된다.
4. JwtFilter에서 요청 헤더에 담긴 authorization 토큰을 검증하고 유저 정보를 확인하여 authentication객체를 생성한다.
5. 생성된 authentication객체를 controller에 매개변수로 넘겨준다.
6. controller에서 받은 authetication객체에 getPrincipal() 메소드를 활용하면 인증된 유저 객체를 얻을 수 있다.
1. 먼저 유저가 휴대폰 인증을 완료한 이후 '인증확인' 버튼을 누르게 되면 로그인을 의미하는 http요청이 서버로 들어온다.
- 인증확인 버튼 클릭시
- 클라이언트 -----> HTTP요청메시지[
GET users/me ] -----> 서버
2. 이때 서버에서는 Spring Security의 필터가 이 요청을 가로채 먼저 검증이 필요한 요청인지 확인한다.
../config/SecurityConfig.java파일 실행- 해당 http 요청 URL이
web.ignoring().antMatchers()에 포함되어 있는지 확인
- 포함되어 있지 않다면 모든 http 요청에 대해서 인증을 수행한다.
.anyRequest().authenticated()
web.ignoring().antMatchers(): 이 안에 포함된 요청은 인증을 수행하지 않겠다는 의미
.anyRequest().authenticated(): 모든 요청에대해 인증을 수행하겠다는 의미
3. 검증이 필요한 요청이라면 해당 유저의 로그인 정보를 검증하는 사용자 정의 필터인 JwtFilter가 실행된다.
.addFilterBefore(authFilterContainer.getFilter() : authFilterContainer에서 현재 수행할 필터를 객체를 받아온다.- authConfig.java 파일을 보면
@profile어노테이션을 통해 application.properties 파일에 있는 spring.profiles.active값을 참조하여 해당 값이 local이라면 테스트 필터인 MockAuthFilter를 생성하고 local이 아니라면 실제 인증을 수행하는 JwtFilter가 생성하도록 되어있다.
authFilterConainer.getFilter()는 JwtFilter를 반환한다.
../config/SecurityConfig.java
...생략
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(securedEnabled = true, jsr250Enabled = true, prePostEnabled = true)
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
UserService userService;
@Autowired
private AuthFilterContainer authFilterContainer;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable() // CSRF 보호기능 disable
.authorizeRequests() // 요청에대한 권한 지정
.anyRequest().authenticated() // 모든 요청이 인증되어야한다.
.and()
.addFilterBefore(authFilterContainer.getFilter(),// 커스텀 필터인 JwtFilter를 먼저 수행한다.
UsernamePasswordAuthenticationFilter.class) // 이후 UsernamePasswordAuthenticationFilter 실행
.exceptionHandling() // 예외처리 기능 작동
.authenticationEntryPoint(new HttpStatusEntryPoint(HttpStatus.UNAUTHORIZED)); // 인증실패시처리
}
@Override
public void configure(WebSecurity web) throws Exception {
// 인증 예외 URL설정
web.ignoring().antMatchers(HttpMethod.POST, "/users")
.antMatchers("/")
.antMatchers("/locations")
.antMatchers("/locations/**")
.antMatchers("/courts")
.antMatchers("/courts/**")
.antMatchers(HttpMethod.GET, "/games")
.antMatchers(HttpMethod.GET, "/games/*")
.antMatchers("/assets/**")
.antMatchers("/images/**")
.antMatchers("/favicon.ico")
.antMatchers("/static/**")
.antMatchers("/error")
.antMatchers("/error/**")
.antMatchers("/swagger-ui/", "/swagger-ui/**", "/swagger-resources/**",
"/swagger-ui.html", "/v3/api-docs", "/webjars/**", "/v2/api-docs")
.antMatchers("/users/nickname/**")
.antMatchers("/profile/pic")
.antMatchers("/pages/**")
//.antMatchers(HttpMethod.GET, "/users/**")
;
}
}
../config/auth/AuthConfig.java
...생략
@Configuration
public class AuthConfig {
@Autowired
private UserService userService;
@Bean
@Profile("local")
public AuthFilterContainer mockAuthFilter() {
AuthFilterContainer authFilterContainer = new AuthFilterContainer();
authFilterContainer.setAuthFilter(new MockAuthFilter(userService));
return authFilterContainer;
}
@Bean
@Profile("!local")
public AuthFilterContainer jwtAuthFilter() throws IOException {
AuthFilterContainer authFilterContainer = new AuthFilterContainer();
authFilterContainer.setAuthFilter(new JwtFilter(userService, firebaseAuth()));
return authFilterContainer;
}
...생략
...생략
public class AuthFilterContainer {
private OncePerRequestFilter authFilter;
public void setAuthFilter(final OncePerRequestFilter authFilter) {
this.authFilter = authFilter;
}
public OncePerRequestFilter getFilter() {
return authFilter;
}
}
4. JwtFilter에서 http요청 헤더에 담긴 authorization 토큰을 검증하고 유저 정보를 확인하여 authentication객체를 생성한다.
- http 요청 헤더 중
authorization에 담긴 토큰을 인자로 받아 토큰 형식이 올바른지 확인하는 RequestUtil.getAuthrizationToken() 함수를 실행한다.
RequestUtil.getAuthrizationToken() 함수는 토큰이 {Bearer TOKEN}형태 라면 TOKEN값만 리턴 해주고 그렇지 않다면 예외를 리턴해준다.- 정상적으로 받은
TOKEN값은 firebaseAuth.verifyIdToken() 함수를 통해 유효한 토큰인지 검증을 거치고 유효하지 않다면 예외를 리턴해준다.
userDetailsService.loadUserByUsername(decodedToken.getUid()) uid를 통해 저장된 user를 조회하고 UserDetail객체로 가져온다. 이때 유저가 없으면 예외를 리턴해준다.- 가져온 유저정보를 가지고 유저, 비밀번호, 권한을 매개변수로 받는
UsernamePasswordAuthenticationToken 객체를 생성하여 authentication변수에 저장한다.
SecurityContextHolder.getContext().setAuthentication(authentication) 생성한 authentication객체를 SecurityContextHolder에 넣어준다.
../config/auth/JwtFilter.java
...생략
@Slf4j
public class JwtFilter extends OncePerRequestFilter{
private UserDetailsService userDetailsService;
private FirebaseAuth firebaseAuth;
public JwtFilter(UserDetailsService userDetailsService, FirebaseAuth firebaseAuth){
this.userDetailsService = userDetailsService;
this.firebaseAuth = firebaseAuth;
}
@Override
protected void doFilterInternal (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
FirebaseToken decodedToken;
// 토큰을 받아와 검증
try{
String header = RequestUtil.getAuthorizationToken((request.getHeader("Authorization")));
decodedToken = firebaseAuth.verifyIdToken(header);
} catch (FirebaseAuthException | IllegalArgumentException e){
// ErrorMessage 응답 전송
log.info("token verify exception: " + e.getMessage());
response.setStatus(HttpStatus.SC_UNAUTHORIZED);
response.setContentType("application/json");
response.getWriter().write("{\"code\":\"INVALID_TOKEN\", \"message\":\"" + e.getMessage() + "\"}");
return ;
}
// User를 가져와 SecurityContext에 저장
try{
UserDetails user = userDetailsService.loadUserByUsername(decodedToken.getUid());
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(
user, null, user.getAuthorities());
SecurityContextHolder.getContext().setAuthentication(authentication);
} catch(NoSuchElementException | CustomException e){
log.info("user found exception : " + e.getMessage());
// ErrorMessage 응답 전송
response.setStatus(HttpStatus.SC_NOT_FOUND);
response.setContentType("application/json");
response.getWriter().write("{\"code\":\"USER_NOT_FOUND\"}");
return;
}
// 요청, 응답시 filter호출
filterChain.doFilter(request, response);
}
}
../util/RequestUtil.java
package kr.couchcoding.tennis_together.util;
import kr.couchcoding.tennis_together.exception.CustomException;
import kr.couchcoding.tennis_together.exception.ErrorCode;
public class RequestUtil {
// 헤더값 검증
public static String getAuthorizationToken(String header){
// 헤더값에 Authorization 값이 없거나 유효하지 않은경우
if (header == null || !header.startsWith("Bearer ")){
throw new CustomException(ErrorCode.INVALID_AUTHORIZATION);
}
// parts[0] : bearer, parts[1] : token
String[] parts = header.split(" ");
if (parts.length != 2){
throw new CustomException(ErrorCode.INVALID_AUTHORIZATION);
}
// Token return
return parts[1];
}
}
#2에서 계속!