비트와 바이트
컴퓨터는 정보를 표현하기 위해 전기 신호를 주고받으며 의사소통을 한다.
전기 신호가 있으면 1, 없으면 0, 이때 0 혹은 1의 값이 데이터의 최소 단위가 되고 이를 비트(bit) 라고 표현한다.
따라서 컴퓨터에 저장된 데이터는 0 혹은 1 2진수로 표현되는 것이다.
하지만 이 비트(bit)만 가지고서는 2가지 밖에 표현하지 못하기 때문에 다른 저장 단위가 필요하게 된다.
그래서 연속된 8bit를 묶어 더 많은 값을 표현할 수 있는 바이트(byte)가 등장하게 된다.1byte는 컴퓨터의 최소 저장 단위로서8bit를 의미한다. 00101100과 같은 방식으로 총 2^8가지 즉 256가지의 정보를 표현 가능하다.
아스키코드 (ASCII)
아스키코드는 우리가 사용하는 인간의 언어와 컴퓨터가 사용하는 언어를 매칭시킨 규칙이라고 할 수 있다. 예를 들어 A는 1000001 B는 1000010 과 같이 표현하겠다고 약속한 것이다. 이때 아스키코드는 1바이트의 데이터로 표현 가능하다.

그런데 표를 자세히 보면 1바이트 즉 8비트로 표현되는 것이 아니라 7비트만 사용되는 것처럼 보인다.
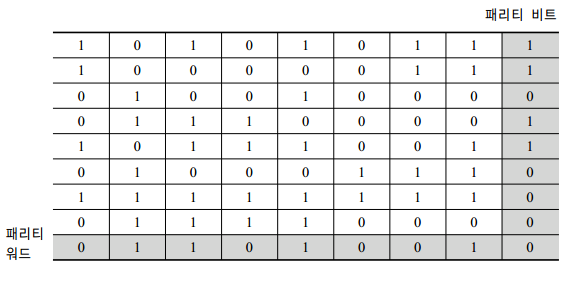
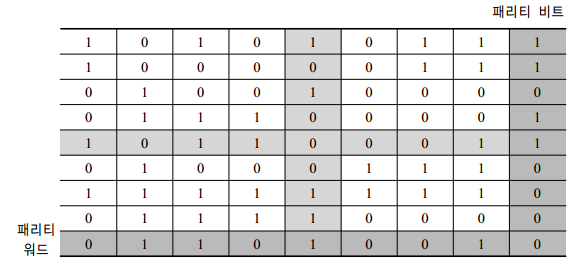
이는 패리티 비트라는 것 때문인데, 간단히 말하면 데이터의 에러를 감지하기 위해 사용되는 비트이다. (링크 : 패리티 비트란 무엇인가)
결국 이를 제외하면 아스키코드는 7비트로 표현가능하기 때문에 총 2^7개인 128개의 문자를 표현할 수 있다.
하지만 128가지로 영어는 모두 표현 가능 했지만, 전 세계의 다양한 문자를 표현하기는 부족했다.
EUC (Extended Unix code)
멀티 바이트를 사용해 한, 중, 일 등의 다양한 언어를 표현하기 위한 인코딩 방식이다.EUC-KR, EUC-JP, EUC-CN 등 다양한 언어를 표현하기 위해 사용되었지만 한계가 있었다.
EUC-KR로 인코딩한 페이지에 한국어와 일본어가 동시에 있다면? 일본어가 깨져버린다. 반대도 마찬가지.
또한 이모티콘도 표현할 수 없었기 때문에 다른 대안이 필요했다.
유니코드
따라서 전 세계 언어의 문자를 정의하기 위한 국제 표준인 유니코드가 등장하게 되었다. (현재까지 약 14만개 문자, 약 2^18비트 필요)
그러나 유니코드 또한 단점이 있는데, 모든 문자를 표현할 수 있지만 메모리 낭비가 너무 심했다. 간단한 문자를 표현하는데도 4바이트씩 필요하게 된 것이다.
간단한 영어는 아스키코드를 사용해 효율적으로 읽고, 다른 언어는 유니코드로 사용하고 싶어서 등장한 것이 대표적으로 UTF-8등의 인코딩 방식들이다.
UTF-8 (8-bit Unicode Transformation Format)
다양한 유니코드 인코딩 방식 중 우리에게 익숙한 UTF-8 방식을 살펴보자.UTF-8은 이름에서도 알 수 있듯이 문자열 집합과 인코딩 형태를 8bit 단위로 한다는 의미를 가지고 있다.
메모리를 효율적으로 사용하기 위해서 문자 하나당 1byte ~ 4byte까지 사용한다.
그렇다면 어떤 문자를 어떤 바이트로 읽을지 어떻게 알 수 있을까?
그것은 첫번째 바이트를 보고 판단할 수 있다.
| 바이트 수 | 첫번째 바이트 | 두번째 바이트 | 세번째 바이트 | 네번째 바이트 |
| 1 | 0xxxxxxx | - | - | - |
| 2 | 110xxxxx | 10xxxxxx | - | - |
| 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | - |
| 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
위 표에 xxx 부분이 실제 문자를 나타내기 위한 비트값이 들어가는 부분이다. 예시를 보자면 다음과 같은 형태로 문자를 읽어들이는 것이다.
| 문자 | 유니코드 코드 포인트 | UTF-8 | 바이트 |
| A | U+0041 (0000 0000 0100 0001) | 01000001 (0x41) | 1btye |
| 걁 | U+AC41 (1010 1100 0100 0001) | 11101010 10110001 10000001 (0xEA 0xB1 0x81) | 3byte |
아스키 코드와도 완벽히 호환되고 UTF-16, UTF-32에서 발생하는 엔디언 문제도 없기 때문에 현재 모든 웹페이지의 93%가 UTF-8을 사용하고 있다.
엔디안 문제 : 1바이트를 초과하는 데이터를 저장할 때 메모리에 어떤 순서로 저장할 것이냐
'개발자의 기본기 > 컴퓨터 기초' 카테고리의 다른 글
| 패리티 비트(parity bit) (0) | 2021.08.10 |
|---|